食べログの得点計算についてのポジティブな可能性を考えるー操作されたデータを検証する難しさー


久しぶりのyahoo個人への投稿となりますが、この記事を公開するのは、正直、気が重いな、と思いつつ、公開します。
というのも、今、食べログに対して非常にネガティブな解釈が広がっているわけですが、何かしらポジティブな材料を提供するとなると、確実にいろいろ言われるだろうなあと思って気が重くて仕方がないのですが、ただ、人生の一時期、食べログにハマっていた人間として、論点として提供されるべきポイントが、提供されていないと感じましたので、本記事を公開する次第です。
◆食べログの評価点数分布の「不自然さ」
さて、近年、食べログの点数評価アルゴリズムは、頻繁にその不正を疑われ議論になっています。
2016年には、評価アルゴリズムのリセットがあった際には、いくつかの店舗がいきなり3.0の点数にリセットされるなどといったことがあり、記事にもなりました。
そして10月8日に、藍屋えんさんという方が、ご自身のブログで書かれた「食べログ3.8問題を検証」というエントリーが現在、大きな話題になっています。
藍屋さんは「評価3.8以上は年会費を払わなければ3.6に下げられる」「食べログが評価を恣意的に操作しているかもしれない」というネット上の噂を紹介した上で、食べログの評価点の分布の偏りを調べ、その分布が正規分布でも、べき分布でもない不思議な分布になっていることをデータとして示し、結果として「これだけでは真相は分かりません」と断りつつも、「他にこの奇妙な偏りを説明することは難しいように思います。」と結んでいます。
ただ、藍屋さんのデータだけでは、藍屋さんの言っていた通り、食べログが本当に悪いことをやっていたかどうかはわかりません。藍屋さんの示したデータによってわかるのは「レビュー件数が一定以上の店舗での分布を見たときに、3.6と3.8の点数の分布に操作がある」という点だけです。
そこで、さらに検証として出てきた記事がkonkonさんによる10月10日の記事「データ解析を駆使して食べログ3.8問題が証明できなかった話」です。こちらでは、食べログ3.6のスコア付近にいる店舗が本当に「食べログにお金を払っていない店舗」(食べログ非会員店舗)が多いのかどうかということを検討しています。藍屋さんは、あくまで、食べログのレビュー件数と、評価点しか見ていませんが、こちらでは食べログの会員か非会員かという要素もデータとして取得しています。
konkonさんのブログでは特に3.6点の店に非会員の店舗が多いという事実は確認できず、藍屋さんが匂わせた「評価3.8以上は年会費を払わなければ3.6に下げられる」という仮説についてはネット上の公開データからは実証できないということを示しています。
また、騒ぎの大きさを受けて、食べログ自体からも10日には公式にコメントが出ています。
長いコメントですが、データの偏りについてコメントされている部分として重要なのは、
「各ユーザーの影響度によって重み付けされた評価をベースとして、お店ごとの点数を算出しております。各ユーザーの影響度は、食べログでの各種実績等から算出しております。」
というポイントです。
これは、前々から食べログが公式に示していたことですが、今回改めて、強調された形の情報です。特殊な計算方法を実装するに至った経緯はよく知られており、基本的には不正業者などを排除することが大きな理由です。(※1)
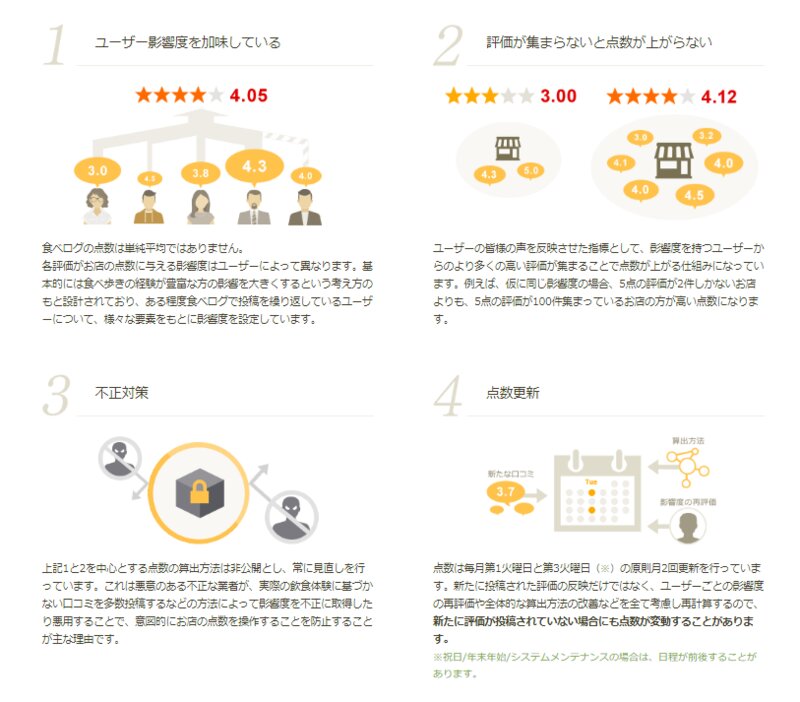
この公式コメントを「食べログは、データに対して操作を加えていない」と紹介されている方もいらっしゃるのですが、そうではありません。食べログは、むしろ、店舗の点数を算出するにあたって複雑な操作を加えていることは、もともと食べログ側は認めているわけです。
ただ、その「操作」の詳細を明らかにしてしまうと、食べログの点数をあげるための裏ワザを提示してしまう可能性もあるため、そのデータ操作の詳細については明らかにできませんと言っているわけです。
この点をブラックボックスにせざるを得ないため、食べログが悪いことをやっているのか、いいことをやっているのか、検証が難しくなっており、問題をややこしくしています。
さて、そういうわけで、食べログのやっているデータに対する「操作」は、実のところどうなっているのか。それが、この炎上の根っこの問題であるわけです。
ただ、現状では、食べログのデータの偏りを食べログの非会員に対する制裁措置として説明しようとするネガティブな仮説からの検討が中心に行われており、食べログの不正対策アルゴリズムの計算の結果であるというポジティブな可能性からの検討が行われていないという状況があります。
つまり、「不自然な分布のデータ」だけが示されており、それが悪いことをした結果なのか、公正な努力の結果なのかは、全くわからない形です。
さて、そこで、かなり不完全なデータではあるのですが、後者の可能性を示すデータの一端を示したいと思います。
◆公開データをもとにどこまで食べログの点数は算出できるか ~7年前の小規模な検証~
私が食べログのヘビーユーザーだったのは、2011年から2012年まででしたので、最近の状況はわかりませんが、当時からすでに分布の偏りっぽいものはヘビーユーザーの肌感覚としてわかりました。3.5付近でなんか処理しているっぽいなと、2012年ごろに私も思いました。
で、「うーん、こりゃ、なんじゃろな」と思い、2012年に食べログの書き込み件数30件前後の店鋪を10店鋪ほど選び、レビューの書き込み情報(全300件程度)を抽出し、それぞれのデータをもとにどうやったら食べログの評点が算出できるのかを丸2日ぐらいかけてやってみたことがあります。
当時は、まさか、食べログのスコアをめぐってこんな大炎上になるとは思っておらず、本当に趣味の延長程度の分析だったので、店舗数が少なくて、とても恐縮ではあるのですが、いろいろと特殊な計算方式をカンだけでいろいろと組み合わせたところ、公開情報のみを元データとして、食べログの点数に近いものを一応、算出できました。
下記は、その際に自分用のメモとしてつくったグラフです。
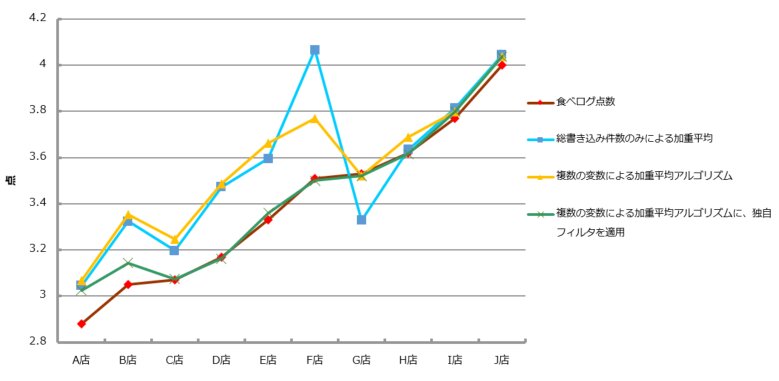
グラフの見方としては、縦軸は点数、横軸は対象とした10店舗を並べたものです。(右に行くほど食べログの点数の高い店舗を並べてあります)
それぞれの線は、
(1)赤い線が食べログの実際の点数そのものです。(ほとんど緑と重なっています)
(2)青い線と、黄色の線が、食べログの評価者の点数を適当に加重平均的な計算をして出したものです。(食べログ自身が、自分たちは加重平均を使っていると公言しているので)。勝手計算その1。
(3)緑の線が「もしかしたら、こういう算出方法使ってるんじゃね?」と思ったものをとにかく色々組み合わせて出したものです。これで、だいたい食べログの点数とほぼ一致しています。勝手計算その2。
現在、ネット上で行われている検証と、私が趣味でやっていたことと違うのは、点数を算出するために、なるべく多くのパラメーターを取得していた点です。というのも、当時、自身がユーザーとして170件ほどの店舗に書き込んで、次のようなことを感じてました。
- 自分の総書き込み件数が100件を越えたあたりで途端に自分の評価が食べログ点数に与える度合いが増えたっぽい
- 数年前の古い書き込みの点数はあまり食べログ点数に反映されず、新しい書き込みのほうが評価されるっぽい
- 総書き込み件数が少ない人の点数は、ほとんど食べログ点数からは無視されてるっぽい
- 3.5付近で評価アルゴリズムがそもそも変わっているっぽい
このため、ユーザーが書き込んだ評価点の他にも
- 書き込みしたユーザーがそれまで書き込んだ数
- 書き込みレビューの日付の新しさ
- レビューに対して参考になった票の数
などを取得して、これをいろいろと組み合わせる計算式を作りました。
私のつくった計算式がそこまできっちり実証的であるとは思っていませんが(※2)、ここで問題にしたいのは、つまり、公開データをもとに、ある程度まで食べログ点数を算出する近似計算ができたのなら、食べログは不正をしていない可能性が十分にあるということをある程度まで示せるだろうということです。食べログ内で公開されているパラメーターを可能な限りすべて取得して、Deep learning的なものに放り込めば、公開情報をもとに食べログの公正性を検討することは可能かもしれません。(※3)
◆不正排除を重視したフィルターによる点数の歪み
さて、2012年に、評価者一人ひとりの評価点に重み付けをして算出し直すと、食べログが公開している評価点に近いものが算出できたわけですが、まあ、これは、人を不可解な気分にさせるだろうなあという部分がありました。
それは、やはり今も問題になっている3.5付近での挙動です。
当時、食べログの挙動と言うのは、どうやらスパムフィルターの挙動に近いのではないか、という感想をもちました。3.5以上になると「問題のある確率が低い店」で、つまり、スパムフィルターを通過している店です。影響力のあるアクティブなレビュアーが書き込みをしていない店は3.5未満になりやすく、いわばスパムフィルターを通過していない店です。単純な平均をとっただけだったら3.8ぐらいになりそうな店も3.4とかだったりしてしまう。店側からしたら、不満が出る措置でしょうが、不正対策としてはこういったアルゴリズムを採用する理由はわからなくはありません。この状況が今回の分布の不自然さに影響をしているのだとすれば、分布を奇妙なものにしていた不正対策のためのアルゴリズムが、不正のように見えてしまっている可能性があるということです。
やや極端に言えば、食べログは評価の分布を適正なものにするよりは、問題のある店に出会わないようにしてくれるためのアルゴリズムを提供することに注力しているため、評価分布は二の次になっているようにも見えました。
とはいえ、これは7年前のことなので、現在はすでに算出方法も変わっているはずです。とは言え、現在も3.5付近での総合的な信頼度による足切りは行われているようで、これは簡単にわかることです。下記は、大阪駅から800メートルの範囲内にある5982件のうち上位1200件のデータと、東京・日本橋エリアで検索した時の、5493件中の上位1200件のデータです。(いずれも2019年10月11日に作成)
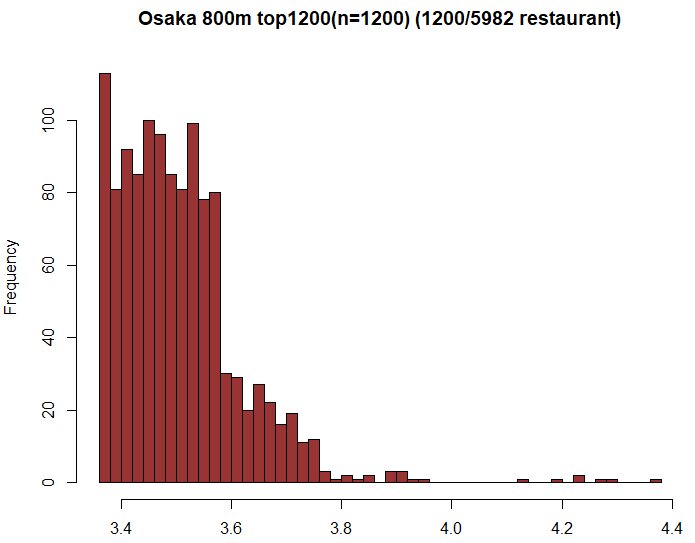
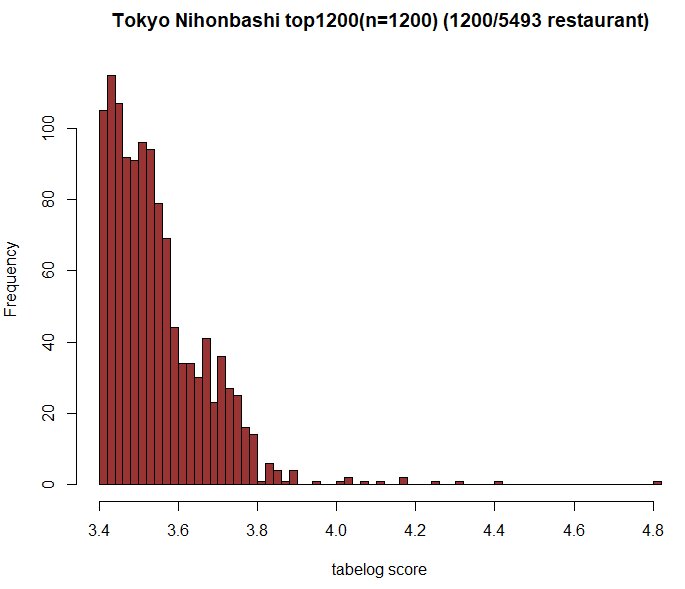
このデータを見ていただければわかりますが、3.6手前と、3.8のあたりでそれぞれ急激に下がっており、何かの手段でふるい落としているのであろうと推定されます。このふるい落としが、いってみれば「秘伝のタレ」というか、いろいろな要素をたくさん混ぜ合わせて、不正を排除して、確実に美味しい店であるかどうかのフィルターを段階的にかけている部分かと思います。
では、なぜ、店舗への書き込み件数が90件を超えたもののみで分布データをとったときに3.6手前に店舗数が多くなってしまうのかは謎は残ります。ただ、これもフィルターの強さという観点から説明できる可能性はあります。
店舗側としては、3.6の壁までは「さまざまなお客さん」からの人気を重ねていけば、点数を重ねられるようになっているわけですが、3.6を越えようと思うと、一定数の「食べログヘビーユーザー」(≒食通)からの支持を得て、「確実にサクラでの点数が入っていない店」であることを頑張って証明する必要がでてくるわけです。一定数の食べログヘビーユーザーを捕まえるということが困難な壁として機能しすぎてしまっているために、「人気はあるけど、食べログヘビーユーザーがあつめられない店」というのが、3.6手前に集まってしまうことになります。特に、不正排除のフィルターを強力にすればするほど、この壁はつよく見えてくることになるでしょう。
◆足切り件数によって変化する点数の壁
さて、いま問題になっているのは100件以上ぐらいのレビュー件数をあつめている店舗の点数分布です。その条件で分布をつくると、3.6手前に店舗数が集中してしまいます。
しかし、これが足切りを100件ではなく、25件にした場合、データの印象は大きく変わります。下の図は、GINK03さんがあつめられた東京エリアの店舗データから足切りを25件で作り直したグラフです。(3.7を上限にして切っていますが、気になる方はこちらを御覧ください。)
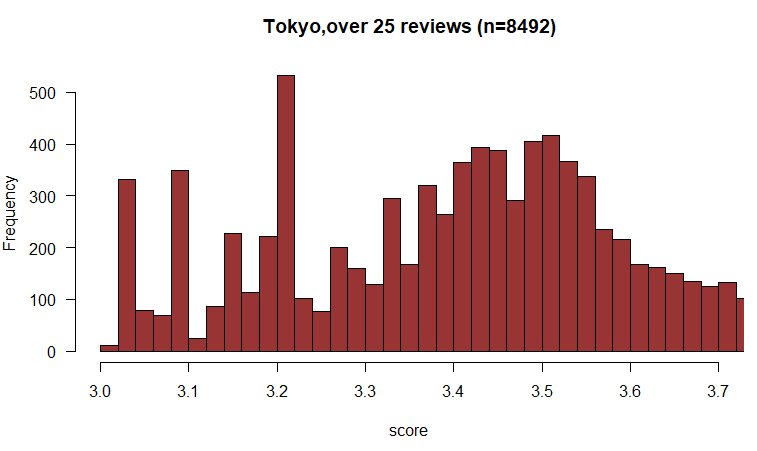
このデータだと、最頻値は3.6の手前ではなく、3.2のところに来ています。つまり、25件ぐらいの書き込みを得られる程度には人気の店にとっては、3.2あたりに仕掛けられているふるい落としのフィルターが高い壁になっているということですね。また、3.02と、3.10のところも壁になっていて、このぐらいの店にとっては、3.6の壁もありまが、どちらかというと3.2が壁になるようです。
では、100件ではなく、もっと敷居を高くして200件以上の書き込みがある店舗を見た場合にはどうでしょうか?こちらもデータを見てみましょう。(範囲を区切っていないデータはこちらを御覧ください)
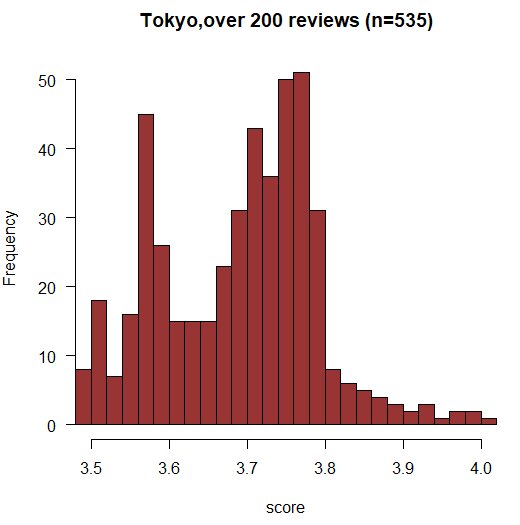
最頻値が、3.8の少し手前に落ち着きました。超人気店だと、ここが壁になってるんですね。
ここからわかるのは、つまり、レビュー書き込み件数の足切りの設定数次第で最頻値(壁)となるポイントが変わるということです。ちょっとした人気店なら3.2に壁があるし、もっと人気の店なら3.6が壁になるし、超人気店なら3.8が壁になっているということがわかります。そして、おそらく0.2ポイントぐらいごとに強めのふるい落としのフィルターがかかっているために、その手前に最頻値が形成されやすいということが伺えます。
これもグラフにして示しておきます。分布図に表示する最低レビュー件数の足切りラインを少しずつ変えて最頻値の変化を確認したものが、下記のグラフです。(※4)
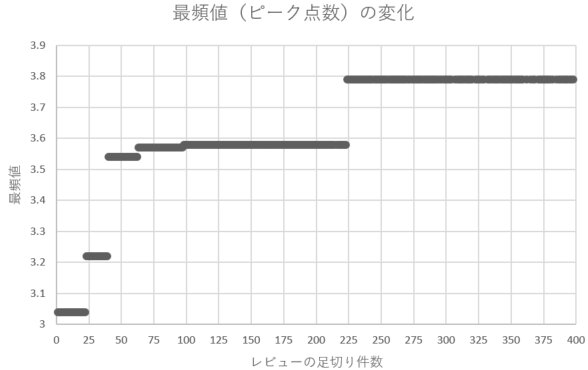
食べログで複数段階で設置されているフィルターが強く壁として機能するポイントが、店舗の人気度合いによって正の相関を描きながら上昇しているのがわかるかと思います。完全に連続的な変化ではなくガクッ、ガクッと変化しているのが、フィルターの存在を明示してますね。
さて、なぜ3.6に最頻値がきてしまうのか?それは、書き込み件数100件~150件ぐらいで足切りしたデータが作られたからです。足切り件数を変えれば最頻値は変わるし、それは「不正」を顕にしたというよりも、食べログのふるい落としフィルターの存在を示したデータといったほうが、穏当な解釈なのではないでしょうか。
とは言え、以上の話で、食べログな不自然な分布のすべてが説明できているわけではなく、食べログの点数算出はいろいろな仕組みが複合的に使われているので、3.6付近に集まってしまう理由を完璧に説明しようと思うとかなり大変ですが、上記のデータで3.6が最頻値になるのは、足切り件数の設定次第なんだなあということはご了解いただけるかと思います。不正対策のアルゴリズム以外も作用している可能性を排除できるわけではありませんが、不正対策のアルゴリズムの作用として説明できる部分もありそうだ、ぐらいに思っていただければいいかと思います。
◆ブラックボックスの評価アルゴリズムをどう考えるか
いずれにせよ、食べログが点数の計算に際して「特殊な操作」をやっているということは、食べログ自身ももともと認めているし、これは第三者がデータを検証しても明らかなことです。ただ、その「特殊な操作」が公正な意図に基づいたものなのかどうかは現状では明らかになっていません。いま、確実にいえる部分は、言えるのはそれ以上でも、それ以下でもありません。
食べログの点数がブラックボックスであるということは、構造的には悩ましいものです。現在、日本の多くの飲食店にとって無視できない影響力をもつようになった食べログのようなネットサービスが公共的な目的に沿ったものかどうかは、可能な限り検討されたほうがよいことで、それはGoogleやFacebookなどが作り出している、ネット上にあるさまざまなアルゴリズムが社会的に望ましいと言える挙動をしているかどうかという問題と同様の論点です。
また、たとえ事業者の当人たちが不正ではないと信じるような運用を行っていたとしても、結果として望ましくないバランスのデータになってしまうことも少なくありません。SNSを通して、人々が触れるニュースに政治的偏りが生まれてしまっていることを検証した研究なども近年では多くあります(※5)。そういったタイプの意図せざる結果として、食べログがさまざまな偏りを内包している可能性は十分にありうることだとは思います。
なお、私自身、さまざまなゲームの「評価」がどのような問題や、偏りをもっているのかを可視化するようなデータセットもつくっています(※6)。何かしらの「評価」を単純平均ではない形で、特殊加工をしてつなぎあわせているデータは世の中にいま非常にたくさんあります。こういったデータをどのように考えていくのか。そのリテラシーを、我々自身がもっと上げていかなければならないのかもしれません。
いまの食べログに対する炎上状況は、かつて、食べログのデータを検討したことのある立場からすると「うーん、悪いことやってる可能性がないとは言わないけど、このデータだけで悪いことやってる証拠だと言うのは、だいぶ無理があるんじゃないのかなあ……。」というのが率直な感想です。今回の炎上はなによりも仕組みがブラックボックスだということが話を大きくしています。
あくまで大筋の原則論ですが、基本的には、私自身は、ブラックボックスではなく可能な限り仕組みを公開していってほしいとは思っています。選挙制度に関わる研究では、制度設計をどう工夫したとしても、たいていなんらかの脆弱性が存在してしまうことが知られています(※7)が、ブラックボックスを隠していても、公開していても、どちらでも脆弱性が存在するのであれば、とくに社会インフラに近い仕組みは可能な範囲で公開して、その脆弱性についての合意を得た上で展開していけるほうが、利用者の納得を得るという意味においてはよかろうとは思います。
しかし、その原則論とは別に、さまざまな社会インフラのアルゴリズムのブラックボックス化がどんどん激しくなっていくことも予想されます。Deep learning的なものが、こういった点数計算に入ってくると、もはや我々の日常言語で説明できるようなレベルをはるかに越える複雑な仕組みになってくるわけで、そうなると算出方法に不正があったのかどうか、その検証について議論する仕組みを作り上げていく努力をする日がくるのかもしれません。
以上、大変ながくなりましたが、私としては、この数日、食べログ関係のネットの意見を見ていると、完全に食べログが悪いことをしたということがあたかも確定したかのように言ってらっしゃる方が多くて、正直なところ、なんだかすごく怖いな、と思いながら過ごしています。この記事をあげるのも本当に怖くて、躊躇いながら、ボタンを押すところです。
もう少し落ち着いて、ネガティブな仮説だけでなく、ポジティブな仮説も含めて検討を行える状況になっていけばよいな、と思います。(※8)
注:
※1 食べログ「点数・ランキングについて」
※2 この算出方法が正しかったと主張するためにはもっと沢山の手続きが必要なので、私の算出方法が正しかったとは主張してません。また、あまりに精度の高いデータを出すと、今度はそれはそれで食べログのアルゴリズムの弱い部分も含めて明らかにしてしまうので、この程度以上のデータを出すとなると、出し方が難しいだろうなあと思います。
※3 こう書くと「おまえがやれ」的なことを言うひとがいるのですが、正直なところその能力はありません。
※4 同じくGINK03さんのデータからとっています。n=28773で、最頻値はここでは0.1単位で取っているため、0.2単位や、0.3単位でデータをつくると少し見え方は変わりますが、概ね似たような感じになります。
※5 最近読んだ、笹原和俊『フェイクニュースを科学する』(2018、化学同人)が、こうした研究についてよくまとめており、とても勉強になりました。
※6 興味のある方は「Game Evaluation Bias Index ver 0.2」 を御覧ください。
※7 坂井 豊貴『多数決を疑う――社会的選択理論とは何か』 (2015、岩波新書) を参照
※8 なお、2012年の私の食べログ点数の検証はマイブームだった当時の私のマイブームパワーでもってやったことです。一応、元データの加工後もgoogle spread sheetとして公開しておきますが、まあ、ほんとに今回のようなことは想定しておらず、趣味でつくったものなので、本人以外には、かなりわからないデータです。(別途、解説ドキュメントをどこかにアップするかもしれません。)
京都に移ってから大学の学食がメインになってしまい、それほど食べ歩きもしていないので、最近の食べログの勘所は衰えています。最近、勘所があるのは主に自作キーボードとかの話なので、この記事をアップしたら、平和な自作キーボード沼に戻りたいです……。ちなみに、この記事は分割40%キーボードのzincで書きました。