人工知能とニュース編集力の交差点と未来~Yahoo! JAPANトップに「はやぶさ2」が自動掲載された理由
(写真:アフロ)
Yahoo!ニュース スタッフブログ読者の皆さま、初めまして。ヤフー株式会社データ&サイエンスソリューション統括本部の村尾一真(むらお・かずま)と申します。Yahoo! JAPANスマートフォン版トップページを対象に、ヤフーの持つビッグデータを活用した機械学習プロダクトのアルゴリズム開発を行っています。今回は、機械学習エンジニアから見た、人工知能とニュース編集の現在と未来について書いていきたいと思います(過去の担当プロダクトはこちらのページをご覧ください)。
広がりゆくニュース×テクノロジー
2015年は、ニュース配信事業においてTwitter・Facebook・Appleといった世界のIT企業がサービスを展開したことが印象的な一年でした。従来のネットメディアが記事を人手で編成していたのと対照的に、これらのサービスは、配信された記事をサービス独自の自動編成でユーザーに提供するという特徴を持っています。独自にはメディア事業を行ってこなかったこれらの企業がこのようなサービスを提供できるようになった背景には何があるのでしょうか。ここには、昨今注目を集めている人工知能(機械学習や自然言語処理技術の総体)の発展が少なからず関わっているとみられます。
2015年は「人工知能」が話題になった年でもありました。その背景のひとつには、近年、深層学習(Deep Learning、機械学習の手法のひとつ)とよばれる技術がコンピュータ性能の大幅な向上などによってブレークスルーを起こし、音声認識や画像処理を筆頭にさまざまな機械学習分野において、研究者を驚かすような高精度を達成したことがあります。深層学習という技術は、用途にあったデータを与えることで汎用的に活用でき、論文やソースコードが広く公開されていることから、今後これらを活用してさまざまな分野で技術革新が起こることが予想されます。当然、先に書いたニュースの自動編成などにもこのような技術が大きく活用されていると推測されるのです。
Yahoo! JAPANトップページの刷新
くしくも2015年は、Yahoo! JAPANのスマートフォン版トップページが刷新された年でもありました。限られたスマートフォンの画面表示領域を有効に活用するために、画面下部のタイムライン部分(画像参照)では、ヤフーの持つビッグデータと機械学習を活用して、それぞれのユーザーに合わせてニュースコンテンツを編成する仕組みを採用しました(ただし上部の6本については、編集者が重要ニュースをピックアップし13文字の見出しをつける「Yahoo!ニュース トピックス」を掲載しています)。
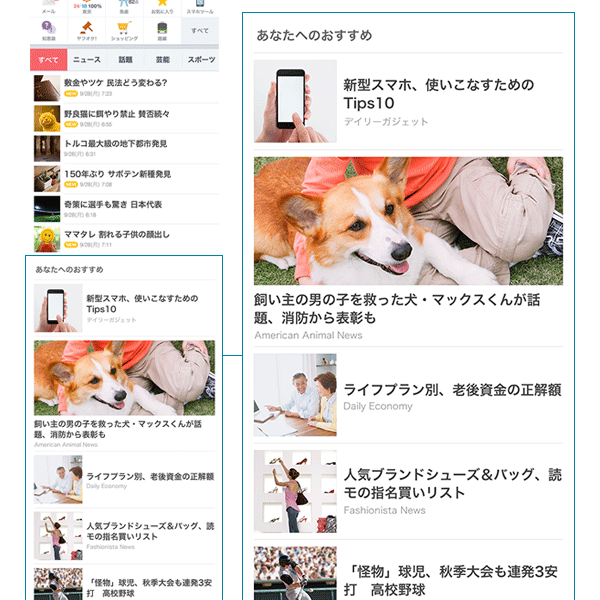
ビッグデータを活用したレコメンデーション
ビッグデータと機械学習を活用し、ユーザー一人ひとりに合わせたコンテンツを提供することによるメリットは大きく2つあります。1つは、ユーザーの興味のあるコンテンツを掲載することでユーザーの満足度を高めることができることです。これは、Eコマースなどで一般的に活用されているレコメンデーションの技術で、ユーザーがサービスを使い込めば使い込むほどその人に合ったコンテンツを掲出できるようになり、ユーザーの利便性が高まります。
実際に、タイムライン部分において個別ユーザーに最適化されたコンテンツを掲出すると、ユーザー全体に最適化されたコンテンツ(ランキングのようなもの)を掲出するよりも平均で30~40%多い記事ページビューを生み出すことができ、より多くのユーザーの関心を引くことができていると考えられます。さらに、最適化されたタイムラインに接触したユーザーは、そうでないユーザーと比較してYahoo! JAPANトップページを繰り返し利用していただけるようになることもわかりました。

もうひとつのメリットは、今までマッチングできなかったニッチな話題と、関心のあるユーザーを結びつけることで、ロングテールの情報提供が可能となることです。
コンテンツパートナーからYahoo!ニュースに配信されている記事は1日に約4000本ですが、Yahoo!ニュース トピックスではこれを編集部が人手で厳選して掲載しているため、掲載できる本数は1日あたり約100本です。一方で、ビッグデータを活用することであなたがフィギュアスケートに関心があることがわかれば、より多彩なフィギュアスケートの記事を読んでいただくことができるようになります。実際に、タイムライン部分ではヤフーに提供いただいているコンテンツを毎日ほぼ余すことなくユーザーにマッチングしています。ビッグデータと機械学習の活用で、今まで情報の山に埋もれていたコンテンツが、適切なユーザーに届く可能性が高まったのです。
不可欠な「ジャーナリズムとの融合」
しかしながら、ユーザーとコンテンツを結ぶという媒介者としての役割を考えたとき、レコメンデーションの仕組みの提供だけをもって機械学習とメディアの融合をうたうことは、車の片輪のみを見ていると言わざるを得ません。なぜなら、ユーザーデータによるレコメンデーションは本質的に、関心の近いユーザー同士の人気投票となっていて、媒介するべきコンテンツとユーザーのうち、ユーザー側のみを向いたプロダクトとなってしまっているからです。報道・ジャーナリズムを担う役割もあるという側面から、掲出すべき記事の価値を測っていくこともまた、人工知能に求められている役割のひとつです。
編集者がニュースをピックアップしてきたYahoo!ニュース トピックスでは、このような観点を考慮してきました。実際に多くの人がクリックするニュースばかりを選んでしまうと、トップページに並ぶトピックスはほとんどがエンタメやスポーツといったジャンルになってしまいます。しかし、Yahoo!ニュース トピックスでは、人々に知ってもらうべき政治や経済などの重要かつ硬派な公共性のあるニュースも欠かさず掲載するように努めてきました。
(※参考:月間閲覧100億超 王者ヤフーニュースの圧倒的強さ - 毎日新聞「経済プレミア」)
このような観点から、Yahoo! JAPANのトップページのタイムライン部分においても、機械学習の力をユーザーの興味関心と公共性のバランスを考慮して割り振っています。そして、よりバランスのとれたタイムラインを構成するためには、公共性や信頼性といったコンテンツのもつ報道観点の「品質」をテクノロジーの力で測っていく取り組みが不可欠なのです。
「はやぶさ2」の自動掲載と公共性判断
実は、このような問題に対する私たちの取り組みはまだ試行錯誤を重ねている段階ですが、ここでは昨年末の「はやぶさ2」のスイングバイ成功のニュースがタイムラインに自動掲載された例をもとに、私たちの取り組みの一部をご紹介したいと思います。「はやぶさ2」については、今でこそ記憶にある方も多いかと思いますが、いわゆる「数字が取りやすい」ジャンルといわれるエンタメやスポーツに比べると硬派な話題ともいえるニュースで、ユーザー行動のデータのみからニュースの価値を予想することは難しいものでした。ではどのようにしてYahoo! JAPANトップページのタイムラインにこのニュースが掲載されたのでしょうか。その流れを追ってみましょう。

※画像はイメージです(写真:アフロ)
2015年12月14日11時、国立研究開発法人宇宙航空研究開発機構(JAXA)から「はやぶさ2」の地球スイングバイが成功し、「Ryugu(リュウグウ)」に向けた進路を航行しているという発表がされました。この一報がYahoo!ニュースに配信され、Yahoo! JAPANトップページのタイムラインに自動掲載されるまでの流れは以下のようになっています。
①NGコンテンツの判定
まず、提供されたコンテンツは、最低限Yahoo! JAPANのトップページに掲出して良い質のものかどうかの自動判断を受けます。例えばアダルト要素を含むものや、取材を経ていないプレスリリースの書き写しなど、トップページに相応しくなく掲載できないようなもの(NGコンテンツ)をフィルタリングする処理を行っています。
②公共性や信頼性の評価
次に、上記のように公共性と社会的関心のタイムライン上でのバランスを取るため、コンテンツがYahoo!ニュース トピックスに掲載されるような内容であるかどうかの判定を行います。このとき、記事で報じられている話題そのものの内容、同一話題の記事が複数の媒体からどれだけ配信されているか、といった観点などから記事の重要度が総合判断されています。
ここでも機械学習の仕組みは有効で、ユーザーによる行動データを用いるのではなく、編集者による、過去から現在までの十数万記事のピックアップ行動のデータを参考に統計的に学習を行うことで、編集者の視点に近い重要度判断を実現しています。「はやぶさ2」が科学領域の堅い話題であること、同月に探査機「あかつき」の金星周回軌道投入のニュースがあったメディア上での話題性などに注目し、それぞれがどう編集者の判断に寄与するかを計算して、それを模倣したコンピュータに予想させているのです。
③話題性の評価
さらに、これらのアルゴリズムによって重要であると判断した記事について、今後の話題度の予想を加味してタイムラインへの掲載を決定します。これらの一連の流れの要所では、深層学習を活用した抽象的な価値判断が行われています。
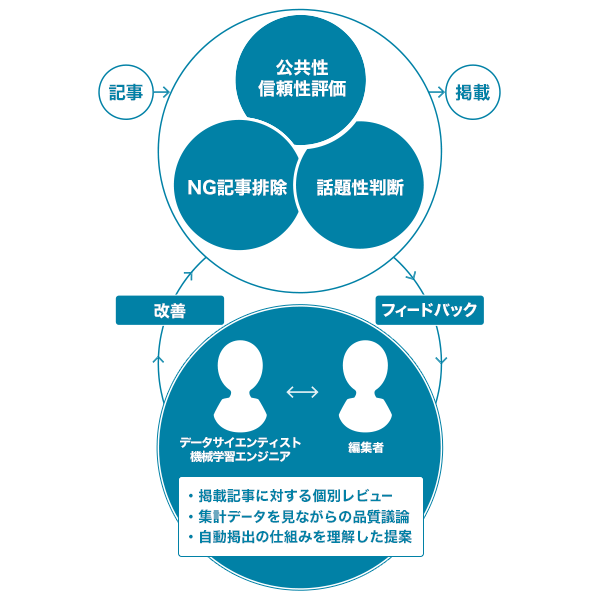
このような一連のアルゴリズムによって「はやぶさ2」のニュース第一報はYahoo! JAPANトップページのタイムラインに自動掲載されました。この「はやぶさ2」のニュースについてはYahoo!ニュース トピックスにも編集者によって取り上げられ、人工知能の予想が編集者による公共性の判断を模倣しつつあると考えられます。上に列挙したように、編集者の観点を取り入れた機械学習の仕組みが重要な役割を果たしているのです。
そして、こうした仕組みを磨き上げるために、ヤフーでは編集者とデータサイエンティストが協力してプロダクトの改善に取り組んでいます(上図参照)。例えば、経験に基づいた専門的な編集知見による掲載記事に対する個別レビューのほか、集計されたデータを照らしあわせての品質議論など、二者で可能な取り組みは多いと実感しています。また限定的ではあるものの、編集者にも自動掲載の仕組みを大まかに理解してもらい、その上で実現できそうな提案をもらう試みを行っており、その可能性について検討もしています。
待ち受ける課題と、未来へのイメージ
一方で、容易に想像がつくことですが、「編集畑」「エンジニア・データサイエンス畑」という全く異なる道を歩んできた専門家同士が、お互いの領域に踏み込んで示唆のある議論を行うことは決してやさしいことではありません。
先日、ある2人の有名人がSNSに投稿した内容を伝えたニュース記事について、なぜ片方はYahoo!ニュース トピックスに掲載され、もう片方はタイムラインに掲載すべきでなかったのかという議論になりました。投稿した内容と投稿者の関係性、出来事や人物についての社会的関心の高まりなど、考慮しなければならない論点は複雑です。熟練した編集者の判断ロジックを機械学習エンジニアやデータサイエンティストが理解するためには、より言語化・ブレークダウンした議論を継続的に重ねることが重要だと強く実感するのです。
冒頭でも述べたように、機械学習・深層学習の進化と発展は2016年もさらに進んでいくことが予想されますし、より「人工知能」のイメージに近づいたさまざまなプロダクトが生まれてくる可能性があるでしょう。海外では、既にニュース記事の一部についてコンピュータに執筆させるような取り組みが実用化されており、遅かれ早かれ国内でもこういった事例が増える日が来ることは間違いありません。一方で、現状の深層学習といえども放っておいて自然と賢くなっていく類のものではなく、その性能向上のためには良質で膨大なデータを与えることが必要であり、ジャーナリズムとして果たすべき役割を学習させるために、そのようなデータと絶えず接触させていく必要があるでしょう。こうした未来において、人工知能を「アシスタント」として編集者が活用していくことは不可欠であると同時に、人工知能をよりよく理解し、関わりあっていく編集力が問われていくのかもしれません。
今回ご紹介したYahoo! JAPANでのニュース編集×人工知能活用の「現場」からの取り組みと課題はほんの一部にすぎませんが、読者の皆さまの、来たるべきテクノロジーの未来をイメージする一助となれば幸いです。
お問い合わせ先
このブログに関するお問い合わせについてはこちらへお願いいたします。